在硅星人首届AI创造者大会上,国家地方共建具身智能机器人创新中心CTO唐剑带来了具身智能发展的全新探索与实践。此次分享以“天工”系列机器人为例,深入展现了如何在多任务、多场景中实现机器人的智慧与灵活操作。中心团队更提出了大模型与具身智能融合的独特视角,旨在推动智能机器人真正走入寻常人家,成为日常生活中的得力助手,赋能未来生活的无限可能。
以下为演讲实录:
感谢主持人,也非常感谢组委会的邀请。今天非常荣幸代表我们具身智能机器人创新中心与大家分享我们最近的一些工作进展,以及我们对未来的展望。
这是我分享的提纲。首先,我想解释一下“天工”这个名字的由来。众所周知,我们发布了人形机器人的名字“天工”,这个名字引用自明代著名学者宋应星的著作《天工开物》,同时,“具身智能体”的一个平台也叫做“开物”。我首先想解释一下,如何让“天工”练成绝世武功,开启万物。具身智能分为两部分:一部分是具身,即人工智能机器人的典型代表;另一部分是智能。接下来,我将介绍我们在“开物”方面的进展和目标。
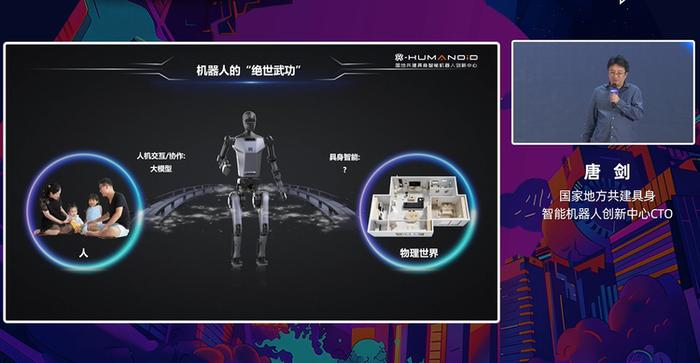
大家可能都看过周星驰在2004年的著名影片《功夫》,里面有一个流行的说法,即要想练成绝世武功,必须打通任督二脉。借助这个比喻,我们如何让机器人练成绝世武功,即操作物理世界的万物,主要涉及两个方面:任督二脉,即人机交互和协作。虽然不能说完全打通,但随着像ChatGPT这样的大模型的出现,我们看到了希望,认为在未来有很大的进展。所谓的督脉,即机器人与物理世界的交互,是这个论坛的主题,目前这个方向非常火热,被称为具身智能。如何打通督脉?目前没有一家公司或科研机构有非常好的解决方案,这也是我们具身智能创新中心研究的重点。

具身智能与机器人技术的进步
上世纪80年代,美国学者莫拉维克提出了莫拉维克悖论。通俗来讲,机器人觉得容易的事情,人类觉得很难;人类觉得难的事情,机器人觉得比较容易。这就是为什么现在我们看到机器人能下棋胜过围棋冠军,而对于洗衣做饭等简单的事情,我们目前还没有大规模落地的应用。这就是为什么以前网上有一个帖子非常火,质疑AI的方向是否搞错了。我们本来希望AI能洗衣做饭,让人去写诗作画,但现在AI却在写诗作画。我认为方向并没有错,对于机器人来说,在千家万户洗衣做饭是非常有挑战性的。因为在非结构化的物理世界里,我们很多操作和工作与工厂结构化程度很强的环境不一样,场景非常不确定。例如,每家的厨房,无论是中式还是西式,甚至各家的中式厨房也都不太一样。
此外,我们在物理世界中的这些工作和任务流程并不固定。我想没有人会给做饭写一个标准操作程序(SOP),规定第一步一定要做什么,第二步一定要做什么,也没有人严格按照SOP来工作。还有多种物品,在开放的物理世界中,哪怕一个杯子都有上千万种,没有人能说得清楚有多少种杯子。还有整个操作过程中可能出现的各种失误情况,这也是为什么自动驾驶大家都很清楚,从2004年开始研究,到现在近20年了,还没有完全实现。因为开车这件事情,在路上会遇到各种各样突发的情况,都必须能解决才行,这是极具挑战性的。
从数据智能到具身智能
我们也注意到AI发展的一个大趋势,即如何将AI应用于物理世界,解决物理世界的问题。整个趋势也是从原先聚焦数据智能,到现在很多人关注具身智能,包括李飞飞提出的空间智能概念,也有异曲同工之妙。这是我们创新中心目前关注的重点。
我们将“具身”和“智能”拆分成两部分,着力研发的主要产品是天工机器人。今年4月底,我们发布了天工1.0版,并在118天内快速迭代,迎来了行业竞争激烈的市场环境。8月底,我们发布了天工1.2版的MAX,具体参数如下:身高约1.73米,与大多数人相似;体重约60公斤,全身拥有42个自由度。不仅可以行走,还具备奔跑能力,速度可达每小时7.2公里。此外,手部配备了灵巧手和传感器,实现了更高的操作精度和感知能力。
稍后我们会正式宣布我们的百台天工计划,即以成本价格向高校、科研院所及科研单位出售我们的天工机器人,并配套开放各类运控、具身智能的接口,同时赠送自研的数据采集设备,可以远程操作机器人采集数据,完成各种工作。
另外,我们还有一个服务机器人,轮臂机器人叫做天轶。后续这个天轶将加上双臂和灵巧手,完成物理操作。
下面我重点介绍一下我们具身智能另一个非常重要的部分,即智能部分。在大模型时代,如何用AIGC技术赋能机器人,也就是我们的开物平台。稍微讲一下历史,因为我之前在高校做科研,以前有不同的名字,现在比较统一叫做具身智能。在大模型出现之前,做具身智能有两个方法,主流的路径:一个叫模仿学习,这是一种监督学习方法,需要大量的数据来训练模型,指导机器人在物理世界完成各种操作。另一个是强化学习,模仿学习非常像跟着教科书、跟着老师学习,强化学习非常像实战派,可能你是一个小白,把你扔在实际环境中学习经验,在物理世界就能做好工作。这是在2021年发布的顶级期刊文章,在非常简单的操作杆上面带着摄像头,人工的视觉校正,物理世界开门、拉门、关抽屉,训练机器人,机器人可以模仿人类做各种操作。

这是在2018年,也是AI顶级会议上发表的文章,用8台KUKA机械臂,100多种物体,强化学习的模型,在这些任务上达到比较好的成功率。大家知道在整个监督学习、强化学习中,各自有各自的优劣势。在大模型出现之前,大家做了很多尝试,因为模型数据、算力等各方面的限制,其实都没有看到非常大规模的机器人在物理世界的应用,除了在工厂环境下的工业机器人,那些都是流程极其固定,甚至轨迹都非常固定的。除了这个之外,在非结构化、半结构化的物理世界里,没有大规模的机器人应用大规模落地。
大脑加小脑的范式思考
在2022年底,随着ChatGPT的出现,也掀起了AIGC浪潮。我们整个做机器人、做具身智能的肯定要思考,这个大模型和机器人结合,会产生怎样的化学反应。我们像ChatGPT这类模型,最强的是它的泛化能力非常强。比如说我基于GPT来做一个问答机器人,之前我们问答机器人都是在某个领域,比如说订票、金融领域的,现在我用GPT这种技术,能做到非常泛化,你基本上聊不死它,可以一直跟它聊天,有时候答案不准确,但是把你的知识库搞好,答案也可以非常准确。我们想如何用大模型来提高机器人的泛化能力。所以现在大模型和具身智能相结合,大家可以看到,比较主流的一种路径,觉得这条路走通了,所谓大脑加小脑的范式。我在云端部署一个大模型,相当于机器人的大脑,它主要做场景的理解和任务的拆解,它要理解这个场景都有什么东西,物品之间的关系、位置如何,以及它们和机器人相对的位置和关系如何。另外一个,就是做任务的拆解,来了一个任务,要把它拆成更小的、非常细力度的子任务,才能对应具体任务的执行。小脑可以是一个运行在机器人身上的智能体,它主要是根据大脑做的任务拆解,去做一些具体技能的执行,并且做一些错误处理。如果发生失误了,比如说我抓这个杯子没有抓起来,我要及时感知到失败,另外重新去做这个操作。
这边举一个具体的例子,用户的指令是“帮我拷一片面包”。我们大脑拆解子任务:拿起面包、放入面包机中、按下面包按钮、等待、放入盘中。具体的智能体,拆解出来的子任务,具身智能体在机器人本体上有一个技能库,具体的执行各种操作。
年底即将发布的开物平台
我们在年底会正式发布我们这个平台,今年先预热一下。其他场合我们CEO也提到,这是一个开物平台,它是具身智能体,但是它是一个分布式多具身智能体。整个扮演这样一个角色,有点像操作系统,其实我们对底下层要适配各类硬件,这就是一脑多机,要支持各种硬件,不只限于天工或者是天轶的平台。所谓用户、方案集成商、应用方案开发商,要非常熟悉物流场景或者是医疗场景,他们在这个基础上,甚至用简单的自然语言编程,甚至做一些简单的低代码的生成,生成这样的应用,控制机器人,完成各种操作,这就是所谓的一脑多能。
前面解释了,我们这个开物是具身智能体,但是它是分布式多具身智能体这样一个系统。在云有一个Brain Agent完成理解、拆解任务,把它对应到各个原技能上。什么是原技能?原技能是一个动词,不带宾语的动词,比如说打开、拿起、放下等等。但是我觉得这个原技能要分场景做不同的原技能,比如说一个OPEN,不一定在家居场景、或者是工业场景、或者是物流场景,放之各种场景皆准,这个非常难。
所以具身智能体扮演的角色跟大模型非常类似,大模型支持人和机器的交互,它让我们做人机交互、人机协作的应用,问答机器人非常简单,投入几个人,几天时间就能干出来。我们开物平台是解决人与物理世界的交互,我们最终目标也是希望你投入很小的团队,不一定几天干出来,这个涉及到更多的维度,比如说在一周或者两周时间就能做出一个机器人下地干活,这个也是主要的目标。
整个这边总结一个特点,我们会用百万级的轨迹数据来训练我们机器人,让它有非常强大的泛化能力,所谓让它能开万物,能操作各种各样不同的在物理世界的物体。另外我们是一个双臂,完成各类操作。同时用原技能向穿珍珠搭积木的方式,适配各种场景,我们希望用这种方式能够很快适配各种场景,而不需要针对某一个场景下的某一个特定任务,专门开发一套程序,这就是整个我们想实现的目的。
另外也是实现在精准的任务拆解,包括复杂任务,几十步的任务都能拆解。总体开物的目标是降低90%的开发时间,就像我们现在用GPT,类似的大模型来做一个人机交互、人机问答的应用,这样一个APP,我可能用很短的时间,很少的投入就可以做成,这也是我们开物,希望我们作为一个机器人的应用,也能在很短时间内完成。
最后也是大家比较感兴趣的,现在在跟行业众多的机器人公司一起合作,也是在政府资金支持下,做一个多本体,有各种各样的机器人,包括各种各样的机械臂,多场景,多任务的数据集。大家知道具身智能非常重要,在网上也看到,前OpenAI首席科学家苏茨克维说,他本来想做人工智能,结果没有大数据,就把这个事情干成了,互联网的数据不是特别有价值,不是特别有帮助,对于机器人训练,它需要的是轨迹数据。我们现在也在做这个,在年底计划要发布30万条有稠密信息的,包括末端执行,以及各个关节,七关节或者六关节,在每个时刻的落地位姿,以及各个传感器,在每个时刻的读数和视觉信息,根据你自己的需要决定如何训练机器人。明年年底打算发布200万条。
后面是一些关键技术和国际顶级会议上发布的学术论文,时间关系简单过一下。这个是做大脑方面相关的叫具身指令增强,我们发现人类指令来了,可能会非常简单,比如说抓起这个玩具熊,如果做一个简单的扩展,指出相应的物品绝对位置,以及它跟机器人相对的位置,把指令扩展以后,我们发现能极大的提升抓取各类操作的成功率。
第二个工作,也是大家都知道,我们把它扩展到多任务,一个VLA的模型,能执行多种任务。
这个是跟单臂做实验,现在很多VLA模型,这个是视频展示多臂实现双臂真正的协同操作,而不是左臂干左臂的事,右臂干右臂的事,这个完全可以实现的,我们不会用很多VLA模型,我们一个VLA模型可以覆盖多种技能。
最后这个工作,我们发现用RGB-D摄像头,也是在人形机器人用的比较广泛的。我们看到第二行,有些黑色的洞,我们提出一个模型能自动补全这些缺失,从而提升各种任务的成功率。
最后想分享的是,上世纪80年代,随着麦金塔图形界面的电脑出现,进入个人电脑时代,2005、2006年,随着iPhone智能手机把人类带入移动互联网时代,每人拥有一台手机,我们坚信未来一定是具身智能机器人时代,千家万户,每家有一台具身智能机器人。我们也希望和在座的各位伙伴,我们各个同行一起共同努力,推动人类进入具身智能机器人时代。谢谢大家!